

Image by chenspec from Pixabay
Random forest is a machine learning method that is commonly used to solve regression and classification problems. It creates tree structure from various samples, using the supermajority for categorization and the average for regression.
One of the most essential characteristics of the Random Forest Algorithm is that it can manage data sets with both continuous and categorical variables, as in regression and classification. For classification difficulties, it produces superior results.
The Analogy to Real Life
To better comprehend this concept, let's look at a real-life example. After completing his 10+2, a student named X wants to choose a college, but he is unsure which subject to take depending on his skill set. As a result, he decides to seek advice from a variety of sources, including his cousins, professors, parents, degree students, and working people. He asks them a variety of questions, such as why he should take that degree, employment chances, course fees, and so on. Finally, after speaking with many individuals about the course, he decides to take the course recommended by the majority of them.
Random Forest Algorithm in Action
We must first learn about the ensemble technique before we can comprehend how the random forest works. Ensemble simply refers to the process of merging multiple models. As a result, rather than using a single model to make predictions, a collection of models is used.
Ensemble employs two types of techniques:
- Bagging– It generates a variety of training subsets with replacement from sample training data, and the outcome is based on popular vote. Take, for instance, Random Forest.
- Boosting– It turns weak students into strong students by generating sequential models with the maximum accuracy possible.
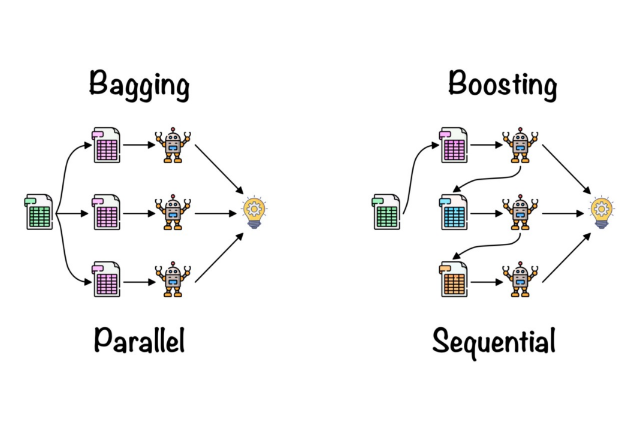
As previously established, Random Forest is based on the Bagging principle.
Let's dive right in and learn everything there is to know about bagging.
Bagging
Bagging, commonly known as Bootstrap Aggregation, is a random forest ensemble approach. Bagging selects a random sample of data from the entire set. As a result, each model is created using row sampling to replace the samples (Bootstrap Samples) provided by the Original Data.
The term "bootstrap" refers to the step of row sampling with replacement. Each model is now trained independently, and the results are generated. After merging the findings of all models, the outcome is based on majority voting. Aggregation is the process of integrating all of the findings and generating output based on majority voting.
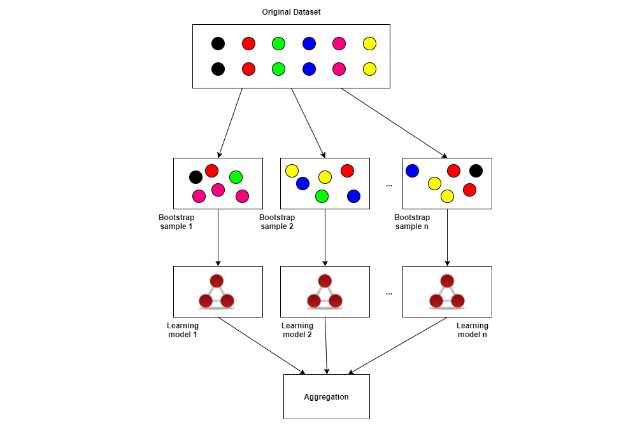
The random forest algorithm has the following steps:
Step 1: In a Random forest, n random records are chosen at random from a data collection of k records.
Step 2: For each sample, individual decision trees are built.
Step 3: Each decision tree produces a result.
Step 4: For classification and regression, the final output is based on Majority Voting or Averaging, accordingly.
Random Forest's Most Important Features
- Diversity- When creating an individual tree, not all attributes/variables/features are taken into account; each tree is unique.
- Immune to the curse of dimensionality- The feature space is minimised because each tree does not consider all of the features.
- Parallelization- Each tree is built from scratch using different data and properties. This means we can fully utilise the CPU to create random forests.
- Train-Test split- In a random forest, there is no need to separate the data for train and test because the decision tree will always miss 30% of the data.
- Stability- Because the outcome is based on a majority vote, there is a sense of stability.
Hyperparameters of Importance
In random forests, hyperparameters are used to either improve the model's performance and predictive capacity or to make it faster.
The predictive power of the following hyperparameters is increased:
- n estimators – the number of trees built by the algorithm before averaging the predictions.
- max features – the number of features that a random forest evaluates while splitting a node.
- mini sample leaf – specifies how many leaves are necessary to separate an internal node.
The following hyperparameters speed up the process:
- n jobs– this parameter tells the engine how many processors it may employ. It can only use one processor if the value is 1, but there is no limit if the value is -1.
- random state– regulates the sample's unpredictability. If the model has a definite value of random state and is given the same hyperparameters and training data, it will always generate the same results.
- oob score– OOB is an abbreviation for "out of the bag." It's a cross-validation method based on random forests. In this case, one-third of the sample is used to evaluate the data rather than train it. These samples are drawn from a bag of samples.
Case Studies
This method is commonly used in fields like e-commerce, banking, medical, and the stock market.
In the banking business, for example, it can be used to predict which customers would default on their loans.
Random Forest Algorithm Advantages and Disadvantages
Advantages
- It can be used to solve problems involving classification and regression.
- It eliminates overfitting because the result is based on a majority vote or average.
- It works well even when there are null or missing values in the data.
- Each decision tree formed is independent of the others, demonstrating the parallelization characteristic.
- Because the average answers from a vast number of trees are used, it is extremely stable.
- It preserves diversity because all traits are not taken into account when creating each decision tree, albeit this is not always the case.
- It is unaffected by the dimensionality curse. The feature space is minimised because each tree does not consider all of the properties.
- We don't need to divide data into train and test groups because the decision tree created out of bootstrap would always miss 30% of the data.
Disadvantages
- When compared to decision trees, where decisions are made by following the route of the tree, the random forest is much more complex.
- Due to its intricacy, training time is longer than for other models. Each decision tree must generate output for the supplied input data whenever it needs to make a prediction.
Final Thoughts
We can now conclude that Random Forest is one of the best high-performance strategies that is widely employed in numerous industries due to its efficacy. It can handle data that is binary, continuous, or categorical.
One of the best aspects of random forest is that it can accept missing variables, so it's a perfect choice for anyone who wants to create a model quickly and efficiently.
Random forest is a fast, simple, versatile, and durable model, but it does have certain drawbacks.